
Last Updated on January 20, 2023, 10:54 am ET

Introduction
Federally mandated policies requiring public access to funded research data have impacted how institutions and researchers support the entire research data life cycle. Without a central infrastructure to support data preservation, researchers store their data contingently in institutional repositories or data repositories, generalist repositories (such as Zenodo), discipline-specific repositories (such as ICPSR), or in other local locations (such as personal websites) to support these mandates. The US National Science Foundation–funded project Realities of Academic Data Sharing (RADS) aims to uncover where researchers are sharing their research data to make it publicly accessible, and aims to assess quality of metadata for these data as measured by metadata completeness. Specifically, RADS is examining where data is stored at Cornell University, Duke University, University of Michigan, University of Minnesota, Virginia Tech, and Washington University in St. Louis. Detailed analysis of metadata from The Data Repository for University of Minnesota (DRUM) shows not only the quality of the metadata, but how these metadata connect to the global research data infrastructure.
Metadata’s Journey
During the early days, repositories had metadata collections in one dialect that served, to some degree, all needs: discovery, identification, access, interoperability, and reuse. Native metadata were either hidden from users or were served in the native representation, typically as XML or JSON. Over the last several years, with the emergence of the global research infrastructure (such as DataCite, ORCID, ROR, Crossref / FundRef) and the increase in special-purpose metadata dialects (such as Schema.org, STAC, IGSN), the landscape has changed considerably. In this landscape, metadata can follow many complex pathways, ending up in multiple services and repositories. Metadata can be gained along these paths, but, more typically, they are lost.
Figure 1 illustrates metadata’s journeys through the layers of “Metadata Mountain” in the DRUM at the University of Minnesota. Metadata and documentation are created through active partnerships between researchers and the repository during the submission process. Some of the information is structured (the metadata) and some is unstructured (the documentation), and together they make up the first layer of Metadata Mountain, providing the most complete basis for understanding the data and reproducing scientific results.

Figure 1. Layers of documentation and metadata in the DRUM Repository
The next step on the path up Metadata Mountain is extracting the structured metadata. In the DRUM case, these metadata are represented using Dublin Core and they become the most complete metadata (structured information) for the resource. A subset of these metadata are made available through an OAI-PMH feed in Dublin Core. In the final step up Metadata Mountain, a smaller metadata subset is transferred to DataCite to receive a DOI for the data set. This final subset includes only the mandatory DataCite elements for most data sets, those required for citation: Identifier, Creator, Title, Publisher, Publication Year, Resource Type, and simple access: Landing page URL. This minimal package is not unique to DRUM, it is ubiquitous across most repositories in DataCite (Habermann 2020).
Most of the metadata created in the second layer are no longer included at this point along the path to the top of Metadata Mountain. They remain in the original repository, but they are not available to the global research infrastructure of connections.
This metadata attrition on the climb up Metadata Mountain is not unique to DRUM. Figure 2 compares FAIR completeness scores in four categories from two sets of DataCite records: (1) those created and managed by five RADS institutional repositories (dashed lines) and (2) those created by researchers from the same institutions as part of the submission process into other repositories, such as Zenodo, Dryad, DataVerse, and others (solid lines). The data show that the metadata entered by researchers into other repositories is considerably more complete with respect to these FAIR recommendations than those entered by the institutional repositories. The metadata entered by researchers are from the lower layers of the Metadata Mountain—they exist in the institutional repositories, but they don’t make it to the global infrastructure.

Figure 2. Comparison of FAIRness for DataCite metadata from RADS institutional repositories (dashed red lines) and from data sets submitted by researchers from those same institutions to other repositories (solid green lines)
The schematic depiction of metadata layers in Figure 1 and the data in Figure 2 clearly indicate that differences between metadata content in Metadata Mountain are related to transfer processes rather than to creation processes. When these transfers are improved, attrition along the metadata pathway can be decreased or eliminated, metadata content is maintained, and Metadata Mountain becomes the Metadata Superhighway shown in Figure 3, increasing the content and the potential benefits of the global research infrastructure.

Figure 3. Valuable metadata collected by institutional repositories needs to be included in the global research infrastructure through the entire life cycle to achieve the full potential of the metadata
Improving Completeness of DRUM Metadata in the Global Infrastructure
“Measurement is the first step that leads to control and, eventually, to improvement. If you can’t measure something, you can’t understand it. If you can’t understand it,…you can’t improve it.”
—H. James Harrington in Area Activity Analysis
As Harrington and others have noted, measuring something is the first step towards understanding and improving it. Tools for measuring “FAIRness” of DataCite metadata were described and demonstrated for metadata from ~150 DataCite repositories managed by the German Technical Information Library (TIB). The same approach can be used to quantify FAIRness in DRUM and, more importantly, to measure improvements as new metadata are transferred to DataCite.
Figure 4 shows the results of evaluating FAIRness of DRUM metadata in DataCite, that is associated with DataCite DOIs. The elements included in the evaluation are shown in four groups: FAIR Findable Essential, FAIR Findable Support, FAIR AIR Essential, and FAIR AIR Support, the same groups shown in Figure 2. The pattern seen here is very similar to that seen across all DataCite repositories: the mandatory elements are included in all records, and other elements (recommended and optional) are rare. This reflects the limited “get a DOI” use case that DataCite addresses for most of its members.
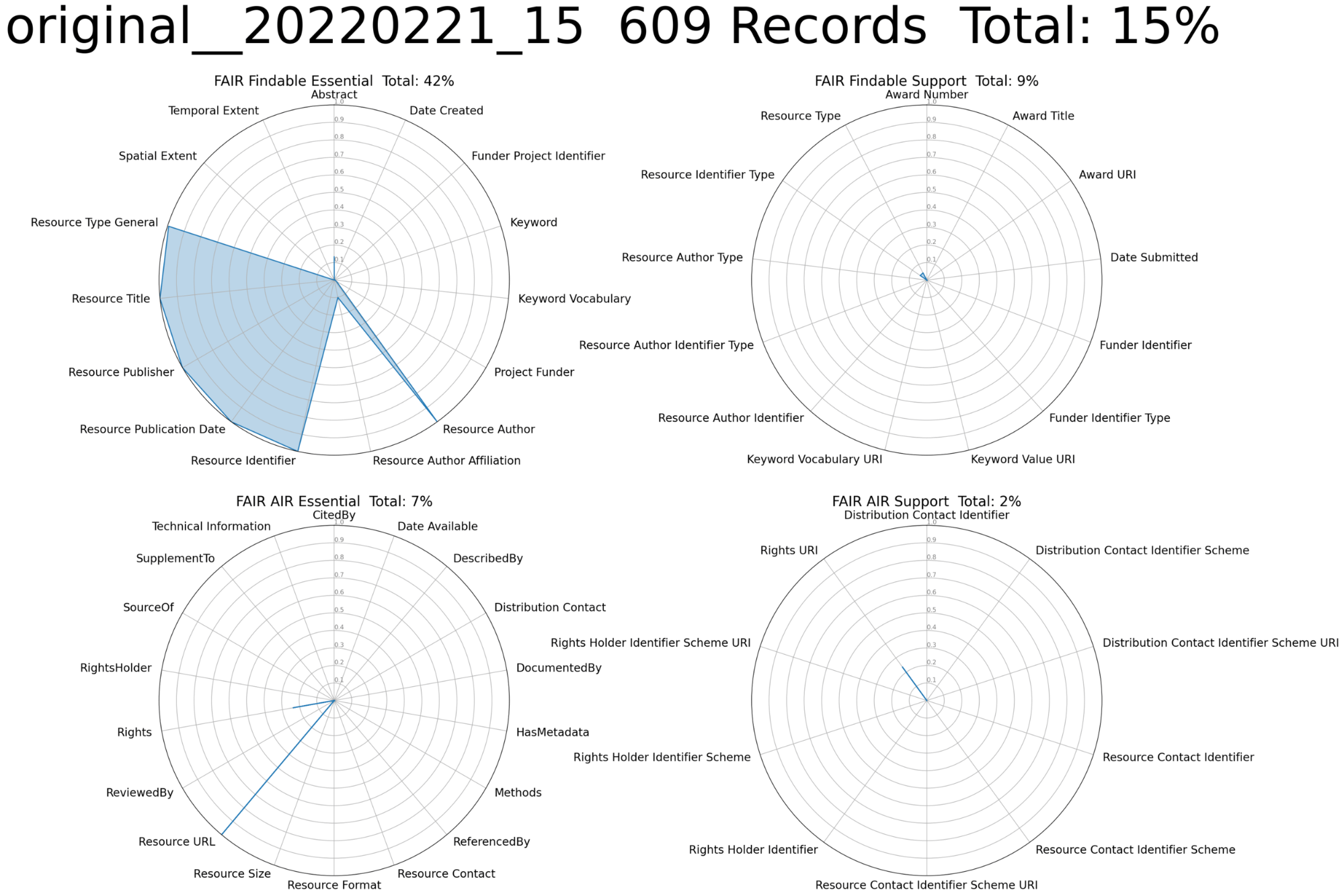
Figure 4. Completeness of 57 DataCite metadata elements related to Findability and Access, Interoperability, and Reusability (AIR) in the DRUM repository
Examining metadata in layer 2 of DRUM, we identified a number of elements populated across many DRUM records but not populated in the DataCite schema. These include elements in all four categories, shown in Table 1. In particular, findability in full-text searches is improved by adding abstracts and keywords to the records; funder search results are improved with funder names, identifiers, and award numbers; connections to papers and other resources are made with ReferencedBy; and reuse is supported with license information and full-text technical information.
| Category | Metadata Concepts |
| Findable Essential | Abstract, Funder, Funder Project Identifier (Award Number), Resource Type, Subject |
| Findable Support | Dates, Funder Identifier, Funder Identifier Type |
| AIR Essential | Dates, ReferencedBy, TechnicalInfo, Rights |
| AIR Support | Rights URI |
Table 1. Metadata concepts added to DataCite from DRUM
The content of these elements was extracted from the DRUM records, translated into the DataCite metadata schema, and used to update the DataCite metadata. Figure 5 shows the evaluation results for the updated records using the same criteria used with the original records. The completeness over all categories improved from 15% to 32%. Figure 5 shows visually striking improvements for many elements related to Findability in the upper left, but the size of the increases in the other categories, from < 10% to > 20% in two cases, are also significant, particularly because these are categories that are generally more difficult to populate.
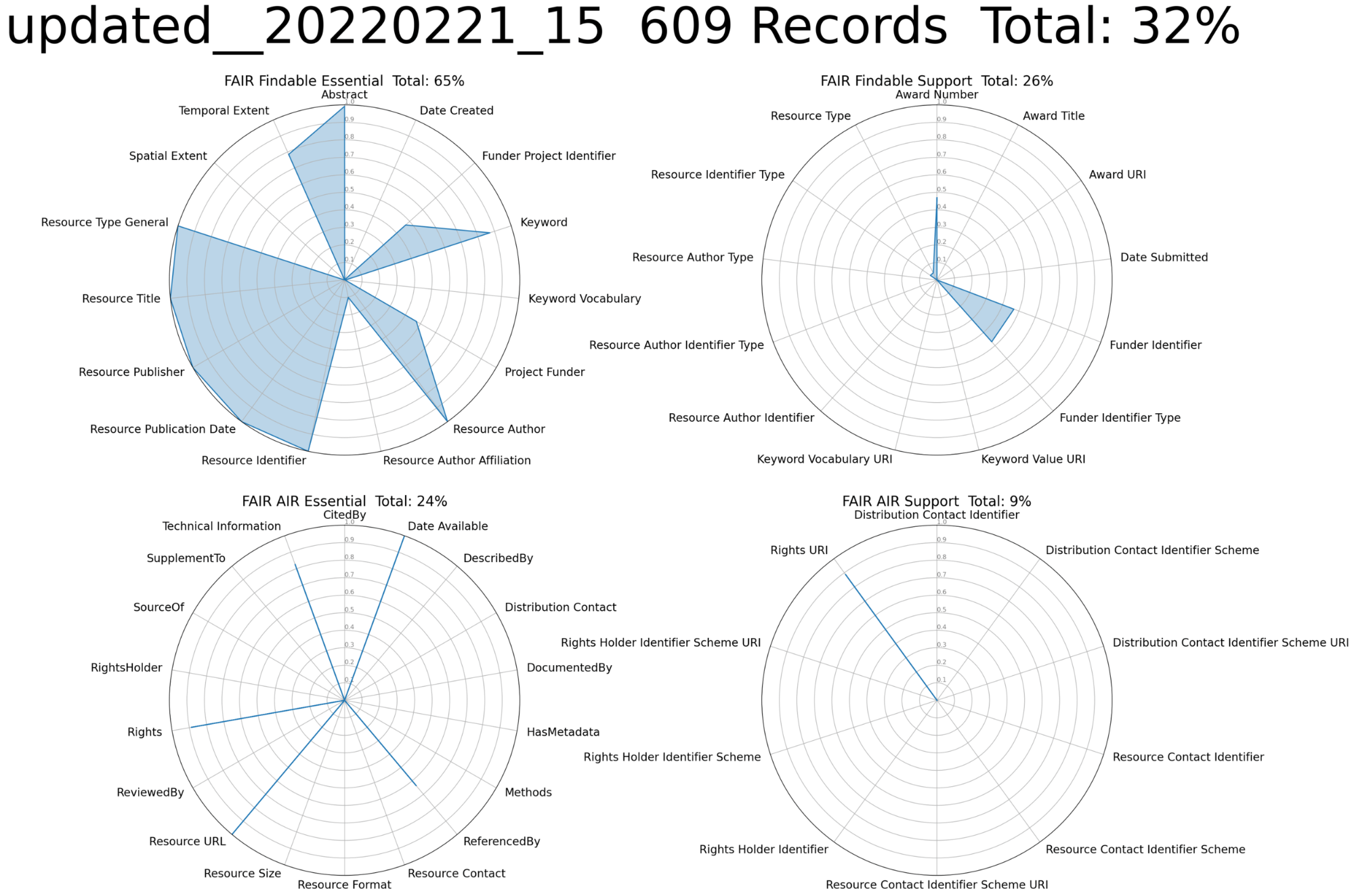
Figure 5. Completeness of 57 DataCite metadata elements related to Findability and Access, Interoperability, and Reusability (AIR) in the DataCite metadata
Conclusion
The most challenging steps along the path up Metadata Mountain occur during metadata creation in partnerships between researchers, data managers, and curators, who many times have different goals on different timescales: short-term goals of getting identifiers so results can be published and long-term goals related to trustworthy data that can be reused. The metadata created during this phase enables all elements of FAIR and is, therefore, the most valuable asset in the system.
Historically the principal role of the global research infrastructure has been to provide persistent identifiers for resources and only minimum metadata, that is the six elements that are complete in Figure 4, are required to get those identifiers. Other valuable metadata are created, but they don’t make it to the summit of Metadata Mountain.
The data in Figure 2 demonstrate the impact that this common practice has on the completeness and FAIRness of metadata in the global research infrastructure, and they demonstrate that the process of metadata transfer to DataCite is an important choke point in populating and increasing the value of the global infrastructure. The impact of improving the transfer process is demonstrated in Figure 4 and Figure 5—significant increases in metadata completeness and in support for all FAIR principles.
Clayton Christensen described the Resources–Processes–Values (RPV) framework for organizational capabilities and the challenges that these elements pose for organizational change. All three of these elements contribute to an organization’s capability for innovation and the difficulty of changing them increases from resources to values. The metadata transfer problem described here is a good example of the process part of this change equation and changing that process is an important step towards change.
Values are the way that people in organizations think and make decisions and small choices about what they do at work. The idea that DataCite exists only to provide DOIs is deeply embedded in repository thought processes and this idea—this value—needs to evolve. The research community needs to think about DataCite, and other elements of the global research infrastructure, as powerful resources for describing and connecting the myriad of resources that make up the connected research world. We need to maximize the information that we add into this system to maximize the return benefits.
Acknowledgments
This work could not have been done without Lisa Johnston, the former director of the Data Repository for the University of Minnesota. Thanks, Lisa!
This work was funded by the US National Science Foundation award 2135874.
Editor’s note: This post was originally published March 7, 2022, on the Metadata Game Changers Blog.


